Tulisan ini merupakan ringkasan dari jurnal yang berjudul “Komputasi Pembobotan Dokumen Berbahasa Indonesia Menggunakan Mapreduce” yang ditulis oleh Fikri Khairul Abror, Wahyu Suadi.
1. Pendahuluan
Menurut penelitian yang dilakukan oleh Gantz et al estimasi data elektronik mencapai 0,18 zettabyte pada tahun 2006 dan diramalkan akan mencapai 1,8 zettabyte pada tahun 2011, data elektronik yang besar tersebut perlu diolah untuk memperoleh manfaat lebih. Adakalanya aplikasi yang dibuat membutuhkan komputer dengan sumber daya yang tinggi sebagai lingkungan implementasi dan biasanya harga untuk komputer dengan sumber daya yang tinggi tidaklah murah sedangkan untuk komputer dengan spesifikasi yang tidak terlalu tinggi akan kurang reliable dalam menangani data yang begitu besar. Untuk melakukan komputasi dengan data yang sangat besar, Google memberikan suatu metode yang dinamakan MapReduce. MapReduce melakukan komputasi dengan membagi beban komputasi dan diproses secara parallel atau bersama-sama. Terinspirasi oleh adanya Google File System (GFS) dan MapReduce yang dikembangkan oleh Google maka Apache mengembangkan Hadoop Distributed File System (HDFS) dan Hadoop MaprReduce framework untuk menyelesaikan permasalahan dengan melibatkan data yang sangat besar yang berbasiskan Java dan open source. HDFS dapat diimplementasikan pada perangkat keras dengan spesifikasi yang tidak terlalu tinggi, hal ini sangat menguntungkan dari segi ekonomi karena selain tidak berbayar, untuk distributed computing yang biasanya memerlukan banyak komputer untuk memproses data.
Kelebihan yang ditawarkan oleh HDFS memberikan peluang untuk menyelesaikan permasalahan pengolahan dengan jumlah data yang besar namun dengan spesifikasi perangkat keras yang tidak terlalu tinggi. Permasalahan yang dibahas di sini yaitu untuk melakukan perhitungan pembobotan dokumen web berbahasa Indonesia. Diharapkan dengan menggunakan HDFS dan MapReduce yang dirilis oleh Apache, beban komputasi pembobotan dokumen dapat dibagi ke dalam beberapa komputer.
2. Metodologi
2.1 Pembobotan Dokumen
Pembobotan kemunculan term dalam suatu dokumen digunakan untuk perhitungan tingkat kemiripan antar dokumen. Ada banyak metode yang dapat digunakan dalam menghitung bobot kemunculan term dalam suatu dokumen. Salah satu yang banyak digunakan adalah menggunakan metode pembobotan TF-IDF Weighting.
TF-IDF Weighting menghitung term dari dokumen yang diwujudkan sebagai sebuah vector dengan elemen sebanyak term yang berhasil dikenali pada proses penghilangan stopword dan stemming. Vector tersebut beranggotakan bobot dari tiap term yang dihitung berdasarkan metode ini. Metode TD-IDF adalah metode yang mengintegrasikan term frequency (tf), dan inverse document frequency (idf) Formula yang digunakan dalam menghitung bobot berdasarkan metode ini yaitu:
w (t, d ) = tf (t, d ) ∗ log N/nt
Bobot suatu term t dalam suatu dokumen d dilambangkan dengan w(t,d). Frekuensi kemunculan term t dalam dokumen d dilambangkan dengan tf(t,d), Sedangkan banyaknya dokumen yang digunakan dalam uji coba dilambangkan dengan N sementara nt adalah banyaknya dokumen yang mengandung term t. Dari formula tersebut diturunkan kembali formula untuk menormalkan term frekuensi sehingga didapatkan formula:
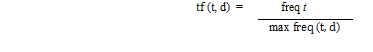
2.2 MapReduce
MapReduce adalah framework software yang diperkenalkan oleh Google dan digunakan untuk mendukung distributed computing yang dijalankan di atas data yang sangat besar dan dijalankan secara simultan dibanyak komputer. Framework ini terinspirasi oleh konsep fungsi map dan reduce yang biasa digunakan di functional programming. MapReduce memungkinkan programmer Google untuk melakukan komputasi yang sederhana dengan menyembunyikan kompleksitas dan detail dari paralelisasi, distribusi data, load balancing dan fault tolerance. MapReduce memiliki dua tahap dalam memproses data yaitu map dan reduce. Tahap pertama dari MapReduce disebut map. Map melakukan transformasi setiap data elemen input menjadi data elemen output. Map dapat dicontohkan dengan suatu fungsi toUpper(str) yang akan mengubah setiap huruf kecil (lowercase) menjadi huruf besar (uppercase). Setiap data elemen huruf kecil (lowercase) yang menjadi input dari fungsi ini akan ditransformasi menjadi data output elemen yang berupa huruf besar (uppercase). Map memiliki fungsi yang dipanggil untuk setiap input yang menghasilkan output pasangan intermediate <key, value>.
Reduce adalah tahap yang dilakukan setelah mapping selesai. Reduce akan memeriksa semua value input dan mengelompokkannya menjadi satu value output. Reduce menghasilkan output pasangan intermediate
2.3 Hadoop
Hadoop adalah framework perangkat lunak berbasis Java dan open source yang berfungsi untuk mengolah data yang sangat besar secara terdistribusi dan berjalan di atas cluster yang terdiri dari beberapa komputer yang saling terhubung. Hadoop dapat mengolah data dalam jumlah yang sangat besar hingga petabyte dan dijalankan di atas ribuan komputer. Hadoop framework mengatur segala macam proses detail sedangkan pengembang aplikasi hanya perlu fokus pada aplikasi logiknya. Hadoop adalah terdiri dari dua komponen yaitu:
1. HDFS (Hadoop Distributed File System) – Data yang terdistribusi.
2. MapReduce – framework dari aplikasi yang terdistribusi
2.3.1 Hadoop Distributed File System
HDFS adalah distributed filesystem berbasis Java yang menyimpan file dalam jumlah besar dan disimpan secara terdistribusi di dalam banyak komputer yang saling berhubungan.

Gambar Arsitektur Hadoop Distributed File System
3. Kesimpulan
Pembuatan suatu aplikasi pembobotan term dokumen berbahasa Indonesia menggunakan bahasa pemrograman Java framework Hadoop MapReduce.
Sumber :
http://digilib.its.ac.id/public/ITS-Undergraduate-14283-paperpdf.pdf
